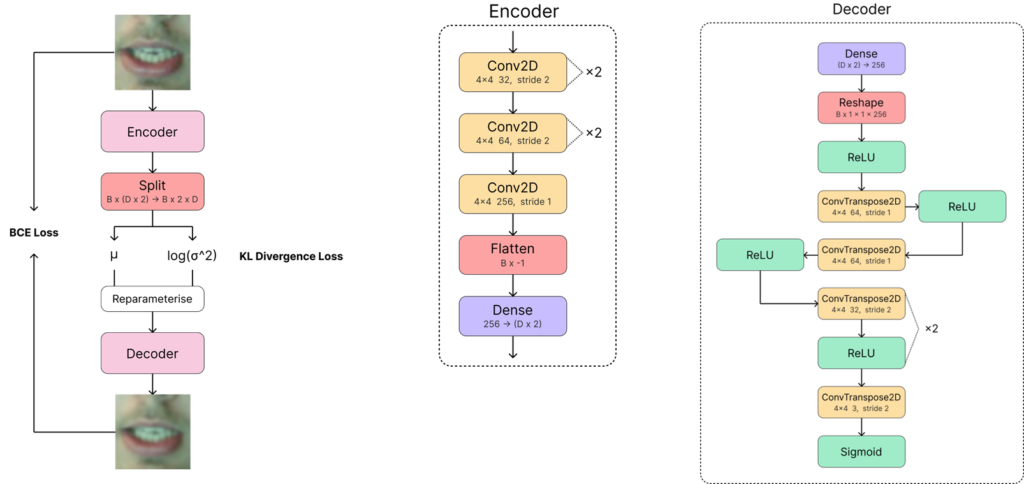
In this coursework, I proposed a state-of-the-art novel approach for lip reading, exploiting a variational autoencoder (VAE) for extracting salient features from video frames using unsupervised learning, improving generalisation and test performance over traditional end-to-end methods. The following figure shows my novel VAE architecture, established using vigorous architectural testing.
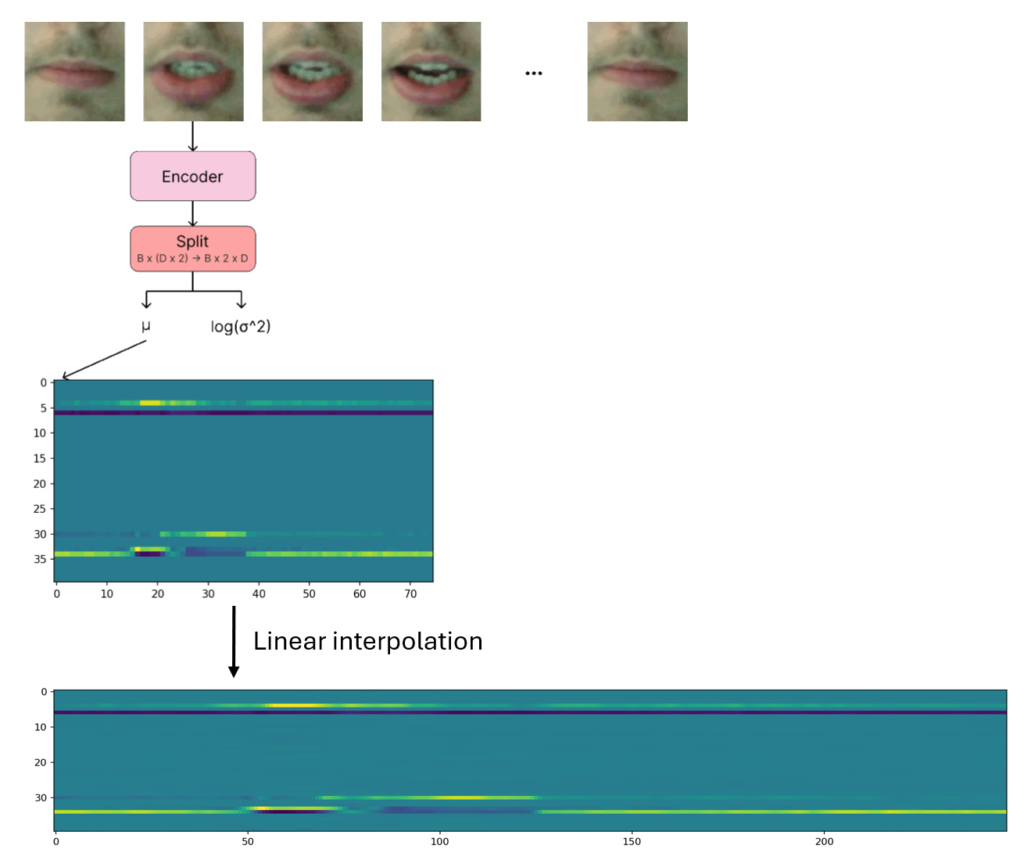
Each video frame was mapped to a latent vector using the VAE, and arranged temporally as a 3-dimensional tensor. This was then upsampled to a frame rate of 30 FPS.
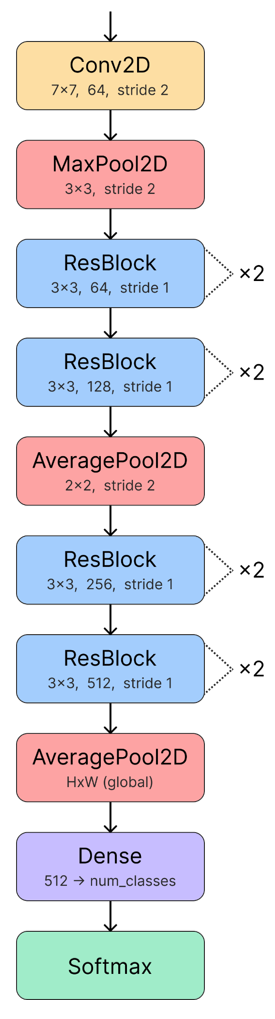
This feature vector was then passed to a standard CNN network. For this, I devised a modified ResNet-18, since I found ResNet-18 to overfit on the latent space features.
As a result, I achieved an accuracy of 93.5% on a self-collected dataset for speech utterance classification. In comparison, the best state-of-the-art approach I tested (using a 3D CNN and BiLSTM) achieved 91%.
Leave a Reply